OLTM: One-Line-Text-Miner β version
Yahoo! JAPANの日本語形態素解析Web APIを使ってワンライナーでテキストマイニングするスクリプトです。Mac OSXのターミナル,もしくはWindows 10のWSL(Windows Subsystem for Linux)のターミナルから実行できます。
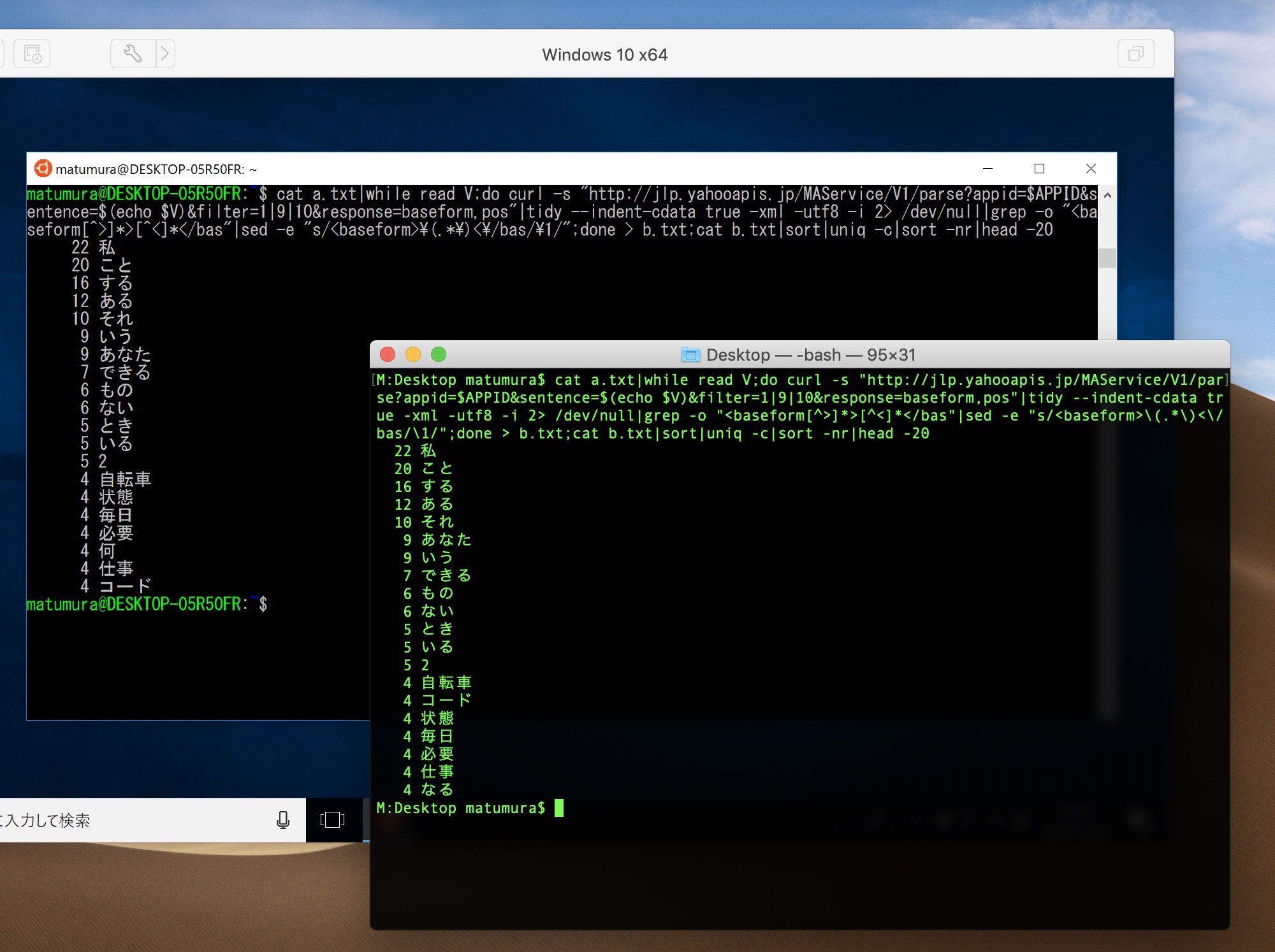
sudo apt install tidyAPPID='dj00...' ← 取得したClient IDを入力してくださいcat a.txt|while read V;do curl -s "https://jlp.yahooapis.jp/MAService/V1/parse?appid=$APPID&sentence=$(echo $V|nkf -WwMQ|sed 's/=$//g'|tr = %|tr -d '\n')&filter=1|9|10&response=baseform,pos"|tidy --indent-cdata true -xml -utf8 -i 2> /dev/null|grep -o "<baseform[^>]*>[^<]*</bas"|sed -e "s/<baseform>\(.*\)<\/bas/\1/";done > b.txt;cat b.txt|sort|uniq -c|sort -nr|head -20cat a.txt|while read V;do curl -s "https://jlp.yahooapis.jp/MAService/V1/parse?appid=$APPID&sentence=$(echo $V|nkf -WwMQ|sed 's/=$//g'|tr = %|tr -d '\n')&filter=1|9|10&response=baseform,pos"|tidy --indent-cdata true -xml -utf8 -i 2> /dev/null|grep -o "<baseform[^>]*>[^<]*</bas"|sed -e "s/<baseform>\(.*\)<\/bas/\1/";done > b.txt;cat b.txt|sort|uniq -c|sort -nr|head -20|awk '{print $1","$2}' > c.csvfilterオプションにより品詞の指定ができます。上記例では「filter=1|9|10」になっているので,形容詞,名詞,動詞を指定しています。
filterに指定可能な品詞番号:
1 : 形容詞
2 : 形容動詞
3 : 感動詞
4 : 副詞
5 : 連体詞
6 : 接続詞
7 : 接頭辞
8 : 接尾辞
9 : 名詞
10 : 動詞
11 : 助詞
12 : 助動詞
13 : 特殊(句読点、カッコ、記号など)
出力単語数を変更するにはheadの引数を変更してください。上記例では「head -20」になっているので,上位20件だけ出力するように指定しています。
Text Mining on the Command Lineにもいろいろ載っています。
OLTMでは,テキストデータを1行ごとにAPIに送ってるので,たとえば100行のテキストデータを分析すると100回リクエストを行います。リクエストの上限は1日5万回(詳しくは利用制限をご覧ください)なので,大きなテキストデータを分析するのには向いていません。その際はTTMをお使いください。
手前がMac OSXの実行結果,奥がWindows 10 WSLの実行結果です。