はじめに
Yahoo! JAPANの日本語形態素解析Web API (V2)を使ってワンライナーでテキストマイニングするスクリプトです。macOSのターミナルだけでなく、Windows 10/11のWSL(Windows Subsystem for Linux)のターミナルからも実行できると思いますが、以下ではmacOSでの使い方のみ説明します。
使い方
- jqコマンドを使うので、ターミナルから以下のコマンドでインストールしてください。
- アプリケーションIDを取得してからターミナルから以下のコマンドを実行して、APPID変数に設定してください。
- 分析したいテキストデータ(サンプルデータはinput.txt、文字コードはUTF-8)を用意してください。
- 以下のスクリプトをターミナルにコピペして実行してください。形容詞、名詞の単語の頻度をカウントして上位20語を出力します。他の品詞を出力したいときは適宜修正してください。
- 出力ファイルをcsvファイルとして保存したいときは、以下のスクリプトを使えば output_utf8.csv と output_shift_jis.csv の2つのファイルが出力されます。
% brew install jq
% APPID='dj00...' ← 取得したClient IDを入力してください
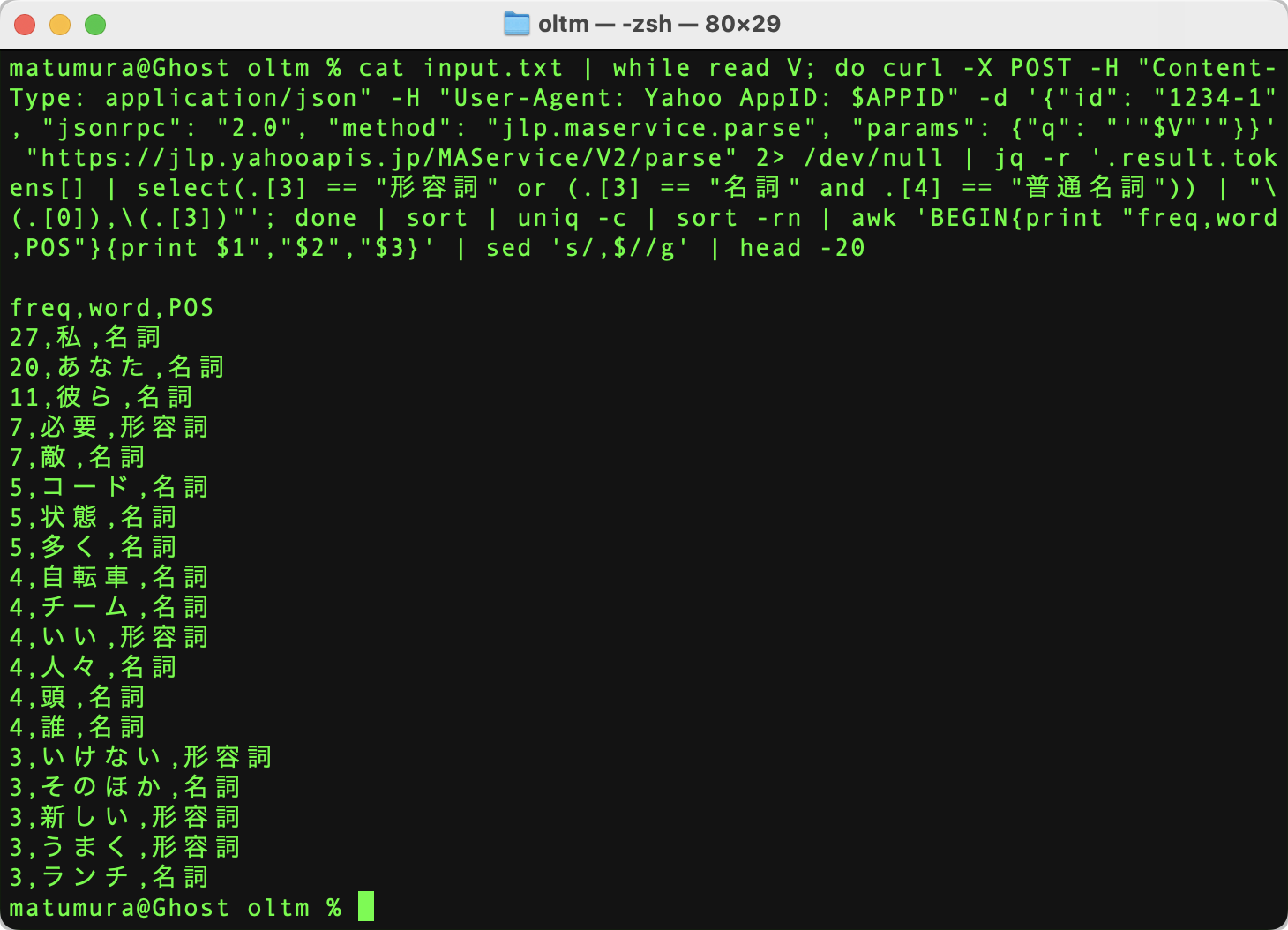
% cat input.txt | while read V; do curl -X POST -H "Content-Type: application/json" -H "User-Agent: Yahoo AppID: $APPID" -d '{"id": "1234-1", "jsonrpc": "2.0", "method": "jlp.maservice.parse", "params": {"q": "'"$V"'"}}' "https://jlp.yahooapis.jp/MAService/V2/parse" 2> /dev/null | jq -r '.result.tokens[] | select(.[3] == "形容詞" or (.[3] == "名詞" and .[4] == "普通名詞")) | "\(.[0]),\(.[3])"'; done | sort | uniq -c | sort -rn | awk 'BEGIN{print "freq,word,POS"}{print $1","$2","$3}' | sed 's/,$//g' | head -20
出力結果は以下のようになります。
% cat input.txt | while read V; do curl -X POST -H "Content-Type: application/json" -H "User-Agent: Yahoo AppID: $APPID" -d '{"id": "1234-1", "jsonrpc": "2.0", "method": "jlp.maservice.parse", "params": {"q": "'"$V"'"}}' "https://jlp.yahooapis.jp/MAService/V2/parse" 2> /dev/null | jq -r '.result.tokens[] | select(.[3] == "形容詞" or (.[3] == "名詞" and .[4] == "普通名詞")) | "\(.[0]),\(.[3])"'; done | sort | uniq -c | sort -rn | awk 'BEGIN{print "freq,word,POS"}{print $1","$2","$3}' | sed 's/,$//g' | head -20 > output_utf8.csv && iconv -f UTF-8 -t SHIFT-JIS output_utf8.csv > output_shift_jis.csv
Web APIの利用制限について
日本語形態素解析Web APIは、1リクエストの最大サイズを4KBに制限しています。また、利用回数については1分で300回を超えた場合に制限がかかります。OLTMではテキストデータを1行ごとにAPIに送ってるので、1分間に分析できるのは300行までになります。また、1行あたり4KB(約2000字くらい)を越えないようにしてください。429 Too Many Requestsのエラーレスポンスが返ってきたときは1分待ってから実行してください。